Updates
awards
positions
publications
service
talks
milestones

Our beautiful baby boy, Runal,
decided to arrive just one day after our wedding anniversary — a wonderful surprise!
Within Google, I moved to the Google Cloud Platform organization. Still working on virtualization projects, but now they live in the digital stratosphere.

My first patent application with Google —
which also happens to be my first one as the first inventor —
was approved for non-provisional filing by the legal team.
Thanks to Google for the filing bonus, the milestone award puzzle piece,
and to my then-manager (Sunil) for a spot bonus!

After a long processing delay,
both my employer-sponsored EB-1B petition (filed by Google)
and my self-petitioned EB-1A petition
were finally approved by USCIS without any RFEs!
My patent with the Automated Reasoning Group at Amazon Web Services on automated analysis of AWS IoT Events Detector Models has been granted.
My third US patent with Microsoft, this time with the RiSE group on table identification, has been granted.
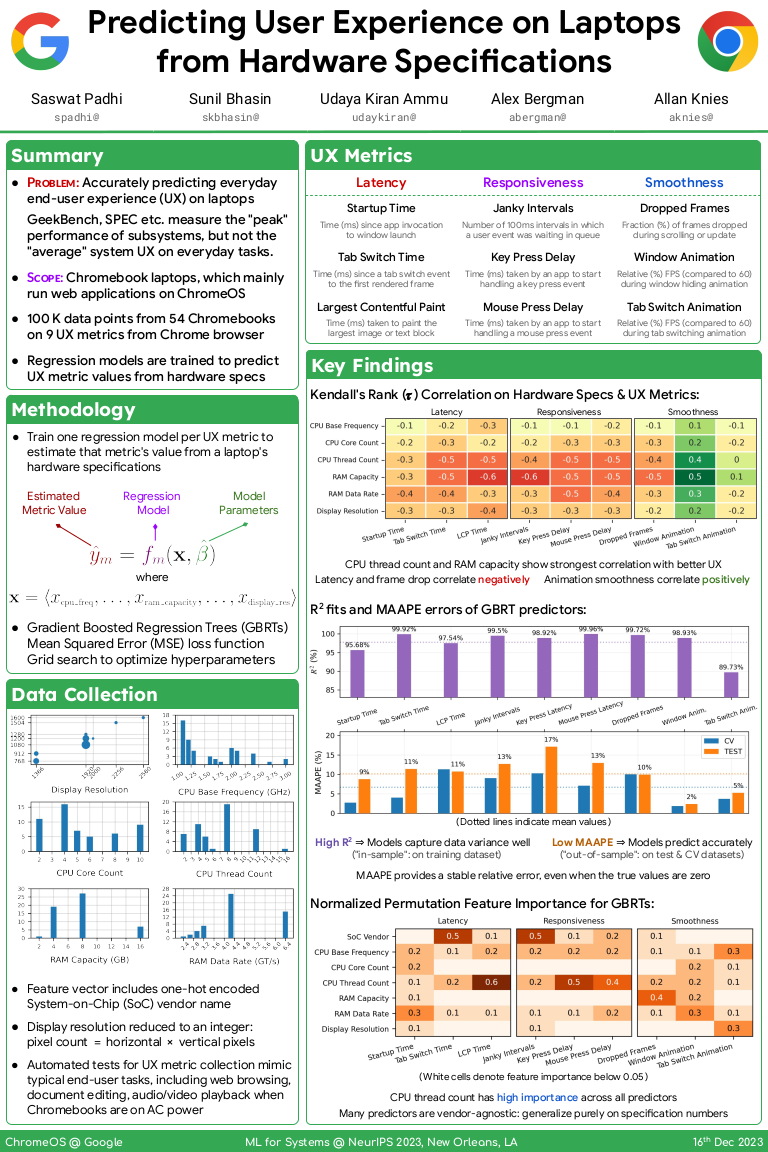
I am presenting our results on UX prediction
at the NeurIPS 2023 workshop on ML for Systems.
In addition to the poster presentation,
our paper is one of 4 papers selected for an oral spotlight presentation as well.
Poster: Predicting User Experience on Laptops from Hardware Specifications
Slides: Predicting User Experience on Laptops from Hardware Specifications
Our research on predicting laptop user experience, with colleagues in chromeOS org at Google, was selected for a poster and oral presentation at the NeurIPS 2023 workshop on ML for Systems.
We present regression-based models for predicting ChromeOS user experience metrics from hardware specifications of Chromebook laptops.
Our work on automated analysis of AWS IoT Events Detector Models, with colleagues in the Automated Reasoning Group at AWS, would appear at CAV 2023 for publication in the Springer-Verlag LNCS series.
We present a collection of automated analyzers that help AWS customers verify that their IoT Event detector models are free of common defects.

My wife, Ruchi, and I were blessed with a beautiful baby girl, Rupal!

After multiple replans and postponements, thanks to COVID,
my wife, Ruchi, and I were finally able to organize our wedding
with our loving family and friends in India.
We released the third iteration of the syntax-guided synthesis (SyGuS) language standard at SYNT 2021.
The major extensions in the SyGuS 2.1 Standard include support for oracles (contributed by Elizabeth Polgreen), a new CHC_X logic (that generalizes the previous Inv_X logic, contributed by me), and a new theory of tables (contributed by Andrew Reynolds and Chenglong Wang).
The 2021 SyGuS competition was postponed,
but we would be adding corresponding new competition tracks in the 2022 competition.
Another patent, with the PROSE group at Microsoft on dataset sampling using program synthesis, was granted (after 4 years)!
Our work on ILP-guided invariant synthesis, with colleagues in the Systems group at Microsoft Research Lab (India), was selected for a poster presentation at the NeurIPS 2020 workshop on Computer-Assisted Programming.
We present a new approach to synthesizing provably sufficient loop invariants by leveraging integer linear programming (ILP).
I joined Michael Whalen’s proof platforms (P2) team within the Automated Reasoning Group (ARG) at Amazon Web Services AWS.
I am honored to be one of four graduating doctoral students in CS who received an Outstanding Research in CS award from the engineering school (HSSEAS) at UCLA.

I successfully defended my thesis (online).
It was an honor to have Adnan Darwiche, Jens Palsberg, Miryung Kim,
Sumit Gulwani, and my advisor Todd Millstein on my committee!
Slides: Data-Driven Learning of Specifications and Invariants
Our Hanoi paper
received a distinguished paper award at PLDI 2020.
This year $5$ out of the $341$ submitted papers received this award.
In UCLA news: Computer Science
Other mentions: PLDI tweet
My work on data-driven inference of representation invariants, with Anders Miltner and Prof. David Walker at Princeton University and my advisor Prof. Todd Millstein, would appear at PLDI 2020.
We present a counterexample-driven algorithm to infer provably sufficient representation invariants that certify correctness of data-structure implementations. Our implementation, Hanoi, can automatically infer representation invariants for several common recursive data structures, such as sets, lists, trees, etc.
My first patent, with the PROSE group at Microsoft on data profiling using program synthesis, was granted! USPTO seems super backlogged — our application was pending for over two years.
I presented our results on overfitting in program synthesis at CAV 2019.
Slides: Overfitting in Synthesis
I am serving on the artifact evaluation committee of the POPL 2020 conference.
See the SIGPLAN Empirical Evaluation Checklist for the “why” and the “how” on conducting rigorous evaluations,
and consider submitting the supporting artifacts for your research papers.
Deadlines: 10th July (papers) · 21st October (artifacts)
I received a travel grant to attend the 31st CAV conference to be held in New York City next month.
I am honored to be one of final-year doctoral students who received the Dissertation-Year fellowship (DYF) awarded by the UCLA Graduate Division.
My work investigating overfitting in SyGuS, with my advisor Prof. Todd Millstein, Aditya Nori, and Rahul Sharma, would appear at CAV 2019 for publication in the Springer-Verlag LNCS series.
We define overfitting in the context of CEGIS-based SyGuS, and show that there exists a tradeoff between expressiveness and performance. We present two mitigation strategies: (1) a black-box approach that any existing tool can use, and (2) a white-box technique called hybrid enumeration.
⋮
Apr19
I am visiting the PL group at Princeton University for the spring quarter. I would be collaborating with Prof. David Walker’s group and my advisor Prof. Todd Millstein, who is currently visiting there as well, on invariant synthesis and related problems.
I am serving on the artifact evaluation committees of SAS 2019 and SPLASH-OOPSLA 2019 conferences.
Artifact evaluation ensures that the results claimed in research papers are easily and accurately reproducible.
Unlike OOPSLA, SAS requests authors of all papers (not just accepted papers) to submit their artifacts,
which are due immediately after the paper submission deadline.
The SAS program committee will also have access to the artifact reviews by the artifact evaluation committee.
SAS Deadlines: 25th April (papers) · 25th April (artifacts)
OOPSLA Deadlines: 5th April (papers) · 8th July (artifacts)
I am joining the organizing committee of the annual SyGuS competition.
Preparations for the 6th SyGuS-Comp,
to be held with SYNT@CAV 2019, have already begun!
Please take a look at the SyGuS language standard v2.0,
and submit your benchmarks and/or solvers.
Deadlines: 1st May (benchmarks) · 14th June (solvers)
I am serving on the program committee of the DebugML workshop at ICLR 2019.
The goal of this workshop is to discuss a variety of topics,
such interpretability, verification, human-in-the-loop debugging etc. to help developers build robust ML models.
Please consider submitting your work.
Deadline: 1st March
An extended version of my undergraduate thesis work on slicing functional programs, with Prasanna Kumar, Prof. Amey Karkare and my then-advisor Prof. Amitabha Sanyal, would appear at CC 2019.
We propose a static analysis for slicing functional programs, which precisely captures structure-transmitted dependencies and provides a weak form of context sensitivity — weakened to guarantee decidability. We also show an incremental version this technique that is efficient in practice.
I am serving as the web manager for the SyGuS group. We recently revamped our website, and are now maintaining repositories for the language standard, tools and benchmarks on our GitHub organization.
I presented FlashProfile at SPLASH-OOPSLA 2018.
Slides: FlashProfile: A Framework for Synthesizing Data Profiles
I am super excited to attend this two-day workshop at the Microsoft Research Redmond campus and meet other Microsoft Research PhD fellows & award winners.
⋮
Sep18
I am interning with Rahul Sharma in the Systems group. I am investigating the expressiveness-vs-performance tradeoff in SyGuS tools, and techniques to efficiently mitigate them.

For the second time, our loop invariant inference tool LoopInvGen
(based on PIE) won the Inv track of SyGuS-Comp 2018.
We received a FLoC Olympic Games medal, which is awarded every 4 years.
We solved $91\%$ of the benchmarks —
was the fastest solver for $89\%$ of them,
and produced the shortest invariants for $74\%$ of them.
In UCLA news: Computer Science
I am serving on the artifact evaluation committee of the SPLASH-OOPSLA 2018 conference. Artifact evaluation ensures that the results claimed in research papers are easily and accurately reproducible.
My research on pattern-based profiling, with PROSE group (at Microsoft) and my advisor Prof. Todd Millstein, would appear at SPLASH-OOPSLA 2018 for publication in the PACMPL journal.
We present a technique, called FlashProfile, to generate hierarchical data profiles. Existing tools, including commercial ones, generate a single flat profile, and are often overly general or incomplete. Furthermore, we show that data profiles can improve accuracy and efficiency of PBE techniques.
⋮
Nov17
As a part-time remote RSDE, I am continuing the exciting work with Ben Zorn, Rishabh Singh (now at Google Brain), and Alex Polozov on generating insights about tabular data in spreadsheets.
Our loop invariant inference tool LoopInvGen (based on PIE) won the Inv track of SyGuS-Comp 2017. On an average, LoopInvGen was ~70x faster than the runner-up (CVC4).

This two-week-long DeepSpec Summer School discussed state-of-the-art techniques
for specifying and verifying of full functional correctness of everything
from low-level hardware instructions to user-level software.
The lectures covered several systems built on top of the Coq proof assistent,
such as the Verified Software Toolchain (VST), CertiKOS, VeLLVM and more.
⋮
Jun17
I am interning with Ben Zorn and Rishabh Singh in the RiSE group, and am working on detecting and repairing inconsistencies in spreadsheet data.
I passed the OQE, and have now advanced to candidacy!
I am honored to be one of the 10 PhD candidates in the US
who were awarded the Microsoft Research PhD fellowship for 2017 – 19.
In UCLA news: Computer Science · Engineering School (HSSEAS)
Other mentions: Microsoft Research blog post · Microsoft Research tweet · HSSEAS tweet
I presented the PIE & LoopInvGen work at the Microsoft Research India lab. (Invited by Rahul Sharma)
⋮
Jun16
I am interning with the PROSE group led by Sumit Gulwani. I am working on efficient syntactic profiling techniques for strings and applying them to improve existing program synthesis techniques.
I presented PIE & LoopInvGen at PLDI 2016.
Slides: Data-Driven Precondition Inference with Learned Features
I presented the PIE & LoopInvGen work at the Software Research Lunch. (Invited by Rahul Sharma)
I presented the PIE & LoopInvGen work to the programming languages and software verification group at UC Berkeley. (Invited by Prof. Sanjit Seshia)
I passed the WQE — one step closer to getting my PhD!
⋮
Mar16
I am a teaching assistant for the upper-division Programming Languages (CS 131) course, taught by my advisor Prof. Todd Millstein, for the second time (after Fall 2014). For those interested, my notes are publicly available in the S16_TA_CS131 repo.
My research on data-driven precondition inference, with Rahul Sharma and my advisor Prof. Todd Millstein, would appear at PLDI 2016.
We present a technique, called the precondition inference engine (PIE), which uses on-demand feature learning to automatically infer a precondition that would satisfy a given postcondition. We use PIE to also construct a novel automatic verification system called LoopInvGen.
I presented my work on data-driven precondition inference at the 15th Southern California Programming Languages and Systems (SoCalPLS) workshop.